基于 Isaac Lab 的 RL 训练、观测量、动作和 Reward 的调整
Prerequisites
注意
下文中的操作在 ROS2GO 512G ISAAC 特别定制版本中有效,不再另行通知。使用 Isaac Sim 的方式是基于/home/tianbot/isaacsim_ws/isaac-sim-standalone@4.5.0/kit/python 这一 Python3.10 环境安装的,所以 请勿随意删除 isaacsim_ws 中的任意出厂内置文件,否则可能会造成原本内置好的 Isaac Sim 4.5.0 + Isaaclab 2.0.0 环境崩溃!!!!!!
提示
如果希望在终端中直接使用 Isaac Sim,首先需要执行以下命令,无需自己重新再配置环境:
source ~/.isaac_env_toolkit && isaac_sim_env准备工作
下载 IsaacLabExtensionTemplate 项目
git clone https://github.com/tianbot/IsaacLabExtensionTemplate.git创建 IsaacLab 自定义 RL 项目
IsaacLabExtensionTemplate仓库中已经贴心的内置了模版的重命名脚本
重命名为自定义项目名称
cd IsaacLabExtensionTemplate && python scripts/rename_template.py tianbot_lab # 这里以tianbot_lab作为自定义项目名称, 如需变更请自行修改安装此自定义项目
为了便于调用与 Isaaclab 的内置 API 一同调用和便于使用,使用 pip install 安装这个自定义本地项目作为 python 第三方依赖包
提示
pip 会解析包的 setup.py 文件,并根据其配置项进行安装。如果对于其它模块的依赖关系已在 setup.py 文件中指定,pip 会自动安装这些依赖包。
python3 -m pip install -e source/tianbot_lab- 验证一下是否正确安装
python3 scripts/rsl_rl/train.py --task=Template-Isaac-Velocity-Rough-Anymal-D-v0如何更新此自定义项目
如果在本地对包进行了修改,可能需要将这些修改更新到已安装的包中。
可以使用以下命令升级本地 Python 包
python3 -m pip install --upgrade source/tianbot_lab 在这里,source/tianbot_lab是此依赖包的本地存放路径如何卸载此自定义项目
如果你想从 Python 环境中卸载本地已安装的包,可以使用以下命令:
python3 -m pip uninstall tianbot_lab # 在这里,tianbot_lab是指要卸载的包的名称项目·目录树结构说明
├── docker # docker compose服务编排相关配置
│ ├── docker-compose.yaml
│ └── Dockerfile
├── LICENCE # 项目许可证
├── logs # train日志文件
│ └── rsl_rl
│ └── anymal_d_flat # 每次anymal_d_flat训练的日志文件
│ └── 2025-03-21_14-02-02
│ ├── events.out.tfevents.1742536929.ros2go.521774.0
│ ├── exported
│ │ ├── policy.onnx # 当前训练轮数最多的模型经过转换后得到的通用格式onnx模型
│ │ └── policy.pt # 当前训练轮数最多的模型
│ ├── git
│ │ ├── IsaacLabExtensionTemplate.diff
│ │ └── rsl_rl.diff
│ ├── model_0.pt # 初始预训练模型
│ ├── model_50.pt
│ ├── model_100.pt
│ ├── model_150.pt
│ ├── model_200.pt
│ ├── model_250.pt
│ ├── model_299.pt # 迭代300轮得到的模型
│ └── params # 训练参数
│ ├── agent.pkl
│ ├── agent.yaml
│ ├── env.pkl
│ └── env.yaml
├── outputs # 训练输出Hydra配置框架日志文件
│ └── 2025-03-21
│ └── 14-02-02
│ └── hydra.log
├── pyproject.toml.bak # 项目配置文件备份
├── README.md # 项目说明文档
├── scripts # 项目可用脚本
│ ├── list_envs.py # 列出所有已注册任务环境
│ ├── rename_template.py # 重命名模板
│ └── rsl_rl # rsl_rl训练脚本
│ ├── cli_args.py
│ ├── play.py # rsl_rl演示脚本
│ └── train.py # rsl_rl训练脚本
└── source # 项目源代码
└── tianbot_lab
├── config
│ └── extension.toml # 插件配置文件
├── docs
│ └── CHANGELOG.rst # 更新日志
├── setup.py # 项目安装配置文件
├── tianbot_lab # 插件主目录
│ ├── __init__.py
│ ├── tasks # 任务环境
│ │ ├── __init__.py
│ │ ├── locomotion # 行走运动任务环境
│ │ │ ├── __init__.py
│ │ │ └── velocity # 速度运动任务环境
│ │ │ ├── config # 任务环境配置文件
│ │ │ │ ├── anymal_d # 与URDF文件同名的文件夹
│ │ │ │ │ ├── agents
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ └── rsl_rl_ppo_cfg.py # rsl_rl库 ppo算法配置文件
│ │ │ │ │ ├── flat_env_cfg.py # 平坦地形任务环境配置文件
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── rough_env_cfg.py # 粗糙地形任务环境配置文件
│ │ │ │ ├── __init__.py
│ │ │ ├── __init__.py # 模块入口文件
│ │ │ ├── mdp # 任务环境MDP (马尔科夫随机过程)模块
│ │ │ │ ├── curriculums.py # 任务环境课程配置模块
│ │ │ │ ├── __init__.py
│ │ │ │ └── rewards.py # 任务环境奖励模块
│ │ │ └── velocity_env_cfg.py # 速度任务环境配置文件
│ └── ui_extension_example.py项目结构表格说明
| 文件路径 | 作用描述 |
|---|---|
| docker/docker-compose.yaml | Docker Compose 服务编排配置文件 |
| docker/Dockerfile | Docker 镜像构建文件 |
| LICENCE | 项目许可证文件 |
| logs/rsl_rl/anymal_d_flat/2025-03-21_14-02-02/events.out.tfevents.1742536929.ros2go.521774.0 | TensorBoard 训练事件日志 |
| logs/rsl_rl/anymal_d_flat/2025-03-21_14-02-02/exported/policy.onnx | 导出的 ONNX 格式策略模型 |
| logs/rsl_rl/anymal_d_flat/2025-03-21_14-02-02/exported/policy.pt | PyTorch 格式策略模型 |
| logs/rsl_rl/anymal_d_flat/2025-03-21_14-02-02/git/IsaacLabExtensionTemplate.diff | 扩展模板的 Git 差异文件 |
| logs/rsl_rl/anymal_d_flat/2025-03-21_14-02-02/git/rsl_rl.diff | rsl_rl 库的 Git 差异文件 |
| logs/rsl_rl/anymal_d_flat/2025-03-21_14-02-02/model_*.pt | 不同训练阶段的模型检查点 |
| logs/rsl_rl/anymal_d_flat/2025-03-21_14-02-02/params/agent.pkl | 序列化的智能体参数 |
| logs/rsl_rl/anymal_d_flat/2025-03-21_14-02-02/params/agent.yaml | 智能体配置参数文件 |
| logs/rsl_rl/anymal_d_flat/2025-03-21_14-02-02/params/env.pkl | 序列化的环境参数 |
| logs/rsl_rl/anymal_d_flat/2025-03-21_14-02-02/params/env.yaml | 环境配置参数文件 |
| outputs/2025-03-21/14-02-02/hydra.log | Hydra 配置框架日志文件 |
| pyproject.toml.bak | Python 项目配置 |
| README.md | 项目说明文档 |
| scripts/list_envs.py | 列出可用环境的脚本 |
| scripts/rename_template.py | 项目模板重命名脚本 |
| scripts/rsl_rl/cli_args.py | 命令行参数解析模块 |
| scripts/rsl_rl/play.py | 模型推理演示脚本 |
| scripts/rsl_rl/train.py | 训练主程序脚本 |
| source/tianbot_lab/config/extension.toml | 扩展配置文件 |
| source/tianbot_lab/docs/CHANGELOG.rst | 项目更新日志 |
| source/tianbot_lab/setup.py | Python 包安装配置 |
| source/tianbot_lab/tianbot_lab/_init_.py | 包初始化文件 |
| source/tianbot_lab/tianbot_lab/tasks/locomotion/velocity/config/anymal_d/agents/rsl_rl_ppo_cfg.py | PPO 算法配置参数 |
| source/tianbot_lab/tianbot_lab/tasks/locomotion/velocity/config/anymal_d/flat_env_cfg.py | 平坦环境配置 |
| source/tianbot_lab/tianbot_lab/tasks/locomotion/velocity/config/anymal_d/rough_env_cfg.py | 崎岖地形环境配置 |
| source/tianbot_lab/tianbot_lab/tasks/locomotion/velocity/mdp/curriculums.py | 课程学习策略实现 |
| source/tianbot_lab/tianbot_lab/tasks/locomotion/velocity/mdp/rewards.py | 奖励函数定义 |
| source/tianbot_lab/tianbot_lab/tasks/locomotion/velocity/velocity_env_cfg.py | 速度控制环境配置 |
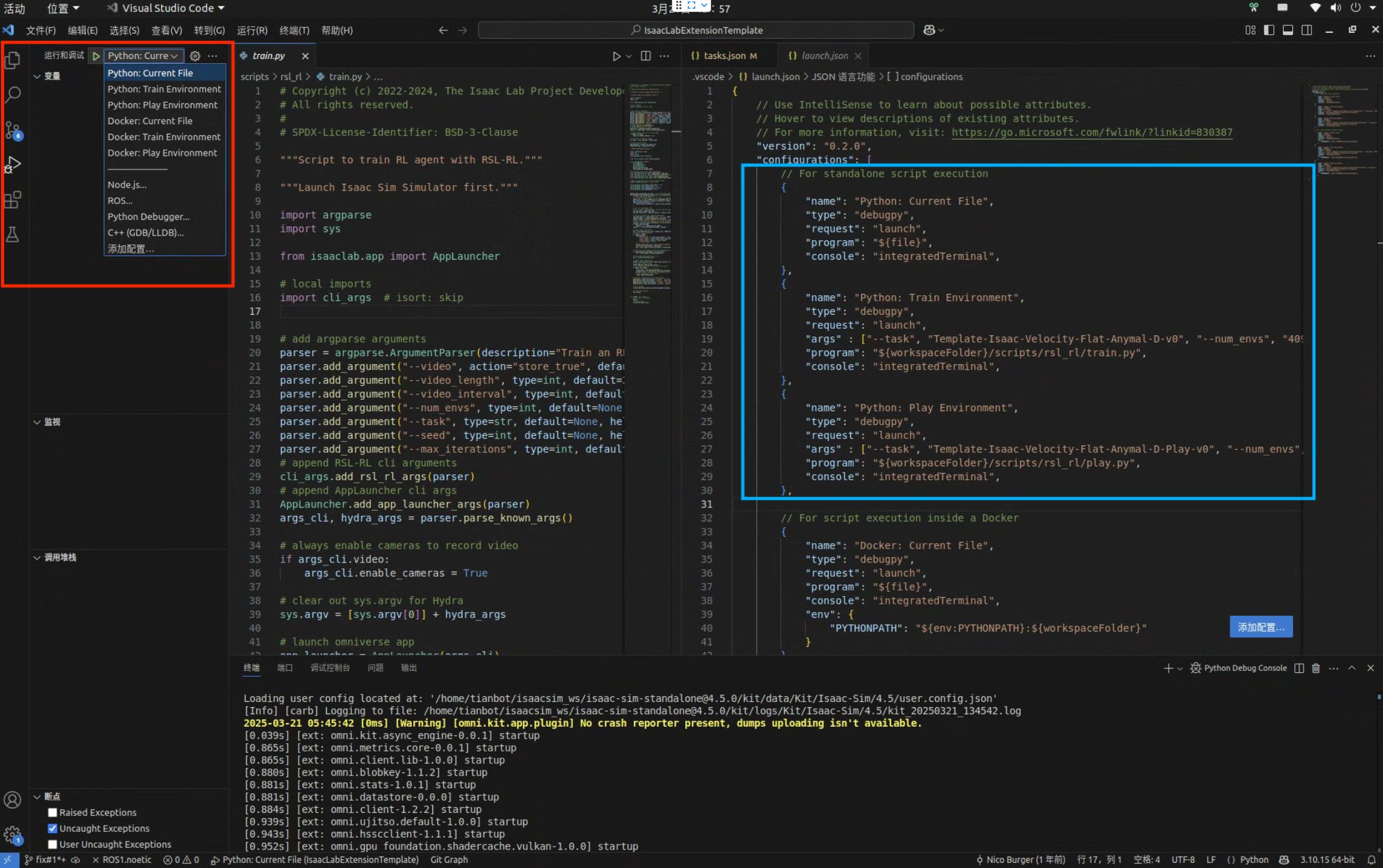
Vscode 配置
cd IsaacLabExtensionTemplate
cp .vscode/tools/launch.template.json .vscode/launch.json # 快捷运行配置文件
cp .vscode/tools/settings.template.json .vscode/settings.json # 系统配置文件为了方便调试,通常会使用一些调试器工具用于 debug,社区的多数基于 isaaclab 的训练任务,都是基于 vscode 进行开发的,其中都会找到.vscode 文件夹。可以参考 github 仓库的.vscode 的配置进行以正确使得 Pylance 提示器生效
如何查看已注册的任务
一般情况下,每个用于 isaaclab 的训练项目在 scripts/目录下都会存在一个 list_envs.py 的可用环境查询脚本,我们运行之后,就会看到相应已经注册的 RL 训练任务
tianbot@ros2go:~/isaacsim_ws/src/IsaacLabExtensionTemplate$ /usr/bin/env /home/tianbot/isaacsim_ws/isaac-sim-standalone@4.5.0/python.sh /home/tianbot/.vscode/extensions/ms-python.debugpy-2025.4.1-linux-x64/bundled/libs/debugpy/adapter/../../debugpy/launcher 59787 -- /home/tianbot/isaacsim_ws/src/IsaacLabExtensionTemplate/scripts/list_envs.py
[INFO][AppLauncher]: Loading experience file: /home/tianbot/isaacsim_ws/IsaacLab-2.0.0/apps/isaaclab.python.headless.kit
Loading user config located at: '/home/tianbot/isaacsim_ws/isaac-sim-standalone@4.5.0/kit/data/Kit/Isaac-Sim/4.5/user.config.json'
[Info] [carb] Logging to file: /home/tianbot/isaacsim_ws/isaac-sim-standalone@4.5.0/kit/logs/Kit/Isaac-Sim/4.5/kit_20250321_133858.log
2025-03-21 05:38:58 [0ms] [Warning] [omni.kit.app.plugin] No crash reporter present, dumps uploading isn't available.
2025-03-21 05:38:59 [1,145ms] [Warning] [omni.usd_config.extension] Enable omni.materialx.libs extension to use MaterialX
2025-03-21 05:39:00 [1,985ms] [Warning] [omni.isaac.dynamic_control] omni.isaac.dynamic_control is deprecated as of Isaac Sim 4.5. No action is needed from end-users.
|---------------------------------------------------------------------------------------------|
| Driver Version: 570.86.10 | Graphics API: Vulkan
|=============================================================================================|
| GPU | Name | Active | LDA | GPU Memory | Vendor-ID | LUID |
| | | | | | Device-ID | UUID |
| | | | | | Bus-ID | |
|---------------------------------------------------------------------------------------------|
| 0 | NVIDIA GeForce RTX 4090 D | Yes: 0 | | 24564 MB | 10de | 0 |
| | | | | | 2685 | 0dc98af2.. |
| | | | | | 1 | |
|=============================================================================================|
| OS: 20.04.6 LTS (Focal Fossa) ubuntu, Version: 20.04.6, Kernel: 6.13.6-ros2go
| XServer Vendor: The X.Org Foundation, XServer Version: 12013000 (1.20.13.0)
| Processor: Intel(R) Core(TM) i9-14900KF
| Cores: 24 | Logical Cores: 32
|---------------------------------------------------------------------------------------------|
| Total Memory (MB): 128645 | Free Memory: 120529
| Total Page/Swap (MB): 64322 | Free Page/Swap: 64322
|---------------------------------------------------------------------------------------------|
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Available Environments in Isaac Lab Template Extension |
+--------+------------------------------------------------+---------------------------------+-------------------------------------------------------------------------------------------------------+
| S. No. | Task Name | Entry Point | Config |
+--------+------------------------------------------------+---------------------------------+-------------------------------------------------------------------------------------------------------+
| 1 | Template-Isaac-Velocity-Flat-Anymal-D-v0 | isaaclab.envs:ManagerBasedRLEnv | <class 'tianbot_lab.tasks.locomotion.velocity.config.anymal_d.flat_env_cfg.AnymalDFlatEnvCfg'> |
| 2 | Template-Isaac-Velocity-Flat-Anymal-D-Play-v0 | isaaclab.envs:ManagerBasedRLEnv | <class 'tianbot_lab.tasks.locomotion.velocity.config.anymal_d.flat_env_cfg.AnymalDFlatEnvCfg_PLAY'> |
| 3 | Template-Isaac-Velocity-Rough-Anymal-D-v0 | isaaclab.envs:ManagerBasedRLEnv | <class 'tianbot_lab.tasks.locomotion.velocity.config.anymal_d.rough_env_cfg.AnymalDRoughEnvCfg'> |
| 4 | Template-Isaac-Velocity-Rough-Anymal-D-Play-v0 | isaaclab.envs:ManagerBasedRLEnv | <class 'tianbot_lab.tasks.locomotion.velocity.config.anymal_d.rough_env_cfg.AnymalDRoughEnvCfg_PLAY'> |
+--------+------------------------------------------------+---------------------------------+-------------------------------------------------------------------------------------------------------+可以看到IsaacLabExtensionTemplate已经注册了 4 个 RL 训练任务,其中Template-Isaac-Velocity-Rough-Anymal-D-v0是IsaacLabExtensionTemplate的默认任务,我们可以通过--task参数来指定使用哪个任务进行训练
如何注册新添加的自定义任务
需要在 config 下每个任务的入口文件中添加任务的相关注册信息,需要添加的关键信息如下:
- 任务 ID:
id - 任务配置参数:
kwargsIsaacLabExtensionTemplate/source/tianbot_lab/tianbot_lab/tasks/locomotion/velocity/config/anymal_d/__init__.py
import gymnasium as gym
from . import agents, flat_env_cfg, rough_env_cfg
##
# Register Gym environments.
##
gym.register(
id="Template-Isaac-Velocity-Flat-Anymal-D-v0", # 任务 ID
entry_point="isaaclab.envs:ManagerBasedRLEnv", # 入口点
disable_env_checker=True,
kwargs={ # 任务配置参数
"env_cfg_entry_point": flat_env_cfg.AnymalDFlatEnvCfg,
"rsl_rl_cfg_entry_point": f"{agents.__name__}.rsl_rl_ppo_cfg:AnymalDFlatPPORunnerCfg",
},
)
gym.register(
id="Template-Isaac-Velocity-Flat-Anymal-D-Play-v0",
entry_point="isaaclab.envs:ManagerBasedRLEnv",
disable_env_checker=True,
kwargs={
"env_cfg_entry_point": flat_env_cfg.AnymalDFlatEnvCfg_PLAY,
"rsl_rl_cfg_entry_point": f"{agents.__name__}.rsl_rl_ppo_cfg:AnymalDFlatPPORunnerCfg",
},
)
gym.register(
id="Template-Isaac-Velocity-Rough-Anymal-D-v0",
entry_point="isaaclab.envs:ManagerBasedRLEnv",
disable_env_checker=True,
kwargs={
"env_cfg_entry_point": rough_env_cfg.AnymalDRoughEnvCfg,
"rsl_rl_cfg_entry_point": f"{agents.__name__}.rsl_rl_ppo_cfg:AnymalDRoughPPORunnerCfg",
},
)
gym.register(
id="Template-Isaac-Velocity-Rough-Anymal-D-Play-v0",
entry_point="isaaclab.envs:ManagerBasedRLEnv",
disable_env_checker=True,
kwargs={
"env_cfg_entry_point": rough_env_cfg.AnymalDRoughEnvCfg_PLAY,
"rsl_rl_cfg_entry_point": f"{agents.__name__}.rsl_rl_ppo_cfg:AnymalDRoughPPORunnerCfg",
},
)source/tianbot_lab/tianbot_lab
├── __init__.py
├── tasks
│ ├── __init__.py
│ ├── locomotion
│ │ ├── __init__.py
│ │ └── velocity
│ │ ├── config
│ │ │ ├── anymal_d
│ │ │ ├── __init__.py
│ │ ├── __init__.py
│ │ ├── mdp
│ │ │ ├── curriculums.py
│ │ │ ├── __init__.py
│ │ │ └── rewards.py
│ │ └── velocity_env_cfg.py
└── ui_extension_example.py如何设置训练时的参数
迭代次数
一般默认是 3000 轮
提示
可以通过设置参数进行手动设置迭代次数,如下所示:
- max_iterations=10000 最大迭代轮数
- headless 无头模式
- checkpoint=/home/tianbot/isaacsim_ws/src/robot_lab/logs/rsl_rl/unitree_b2w_rough/2025-03-13_16-33-32/model_2999.pt 导入模型
python3 scripts/rsl_rl/base/train.py --task RobotLab-Isaac-Velocity-Rough-Unitree-B2W-v0 --headless --checkpoint=/home/tianbot/isaacsim_ws/src/robot_lab/logs/rsl_rl/unitree_b2w_rough/2025-03-13_16-33-32/model_2999.pt --max_iterations=10000如何将当前最新的 policy 导出为 Torch JIT 模型
我们需要运行如下命令,以启动演示任务,其中会将训练好的模型导出为 Torch JIT 模型,便于后续在边缘设备上加载使用
python3 scripts/rsl_rl/base/play.py --task RobotLab-Isaac-Velocity-Rough-Unitree-B2W-v0scripts/rsl_rl/base/play.py 其中的相关代码如下:
# export policy to onnx/jit
export_model_dir = os.path.join(os.path.dirname(resume_path), "exported")
export_policy_as_jit(
ppo_runner.alg.actor_critic, ppo_runner.obs_normalizer, path=export_model_dir, filename="policy.pt"
)
export_policy_as_onnx(
ppo_runner.alg.actor_critic, normalizer=ppo_runner.obs_normalizer, path=export_model_dir, filename="policy.onnx"
)相关 API 接口定义:export_policy_as_jit
如何使用 tensorboard 可视化查看训练日志
tensorboard --logdir=logs资产导入和场景构建
接下来,我们开始介绍如何导入资产和构建场景。对与一个正常速度的 locomotion 任务,我们首先需要做的事是导入资产和构建场景。
提示
Isaa
Scene Definition
class MySceneCfg(InteractiveSceneCfg):
"""Configuration for the terrain scene with a legged robot."""
# ground terrain
terrain = TerrainImporterCfg(
prim_path="/World/ground", # 地面
terrain_type="generator", # 地形类型
terrain_generator=ROUGH_TERRAINS_CFG,
max_init_terrain_level=5,
collision_group=-1,
physics_material=sim_utils.RigidBodyMaterialCfg(
friction_combine_mode="multiply",
restitution_combine_mode="multiply",
static_friction=1.0,
dynamic_friction=1.0,
),
visual_material=sim_utils.MdlFileCfg(
mdl_path="{NVIDIA_NUCLEUS_DIR}/Materials/Base/Architecture/Shingles_01.mdl",
project_uvw=True,
),
debug_vis=False,
)
# robots
robot: ArticulationCfg = MISSING
# sensors
height_scanner = RayCasterCfg( # 高度扫描仪
prim_path="{ENV_REGEX_NS}/Robot/base",
offset=RayCasterCfg.OffsetCfg(pos=(0.0, 0.0, 20.0)), # 高度扫描仪的偏移量
attach_yaw_only=True,
pattern_cfg=patterns.GridPatternCfg(resolution=0.1, size=[1.6, 1.0]), # 设置高度扫描仪的扫描范围
debug_vis=False,
mesh_prim_paths=["/World/ground"],
)
contact_forces = ContactSensorCfg(prim_path="{ENV_REGEX_NS}/Robot/.*", history_length=3, track_air_time=True)
# lights # 光照
light = AssetBaseCfg(
prim_path="/World/light",
spawn=sim_utils.DistantLightCfg(color=(0.75, 0.75, 0.75), intensity=3000.0),
)
sky_light = AssetBaseCfg(
prim_path="/World/skyLight",
spawn=sim_utils.DomeLightCfg(color=(0.13, 0.13, 0.13), intensity=1000.0),
)在MySceneCfg类中,设置了地面、地形、高度扫描传感器、光照。其中,在这里我们可以导入不同的物体,并调整物体初始化的位置、姿态等属性。利用这个设置,我们可以搭建出自己的任务环境,这里你也可以导入一些需要操作的特殊物体,这样就不用再 env_cfg.py 同级的 Config 里导入了。这两个位置可以自由选择,如果更改机器人的时候不更改物体,可以在这里导入物体,但是需要补充一些接口。如果需要在更改机器人时更改物体,建议放在 Config 文件夹下特定机器人的设置中。
MDP (Markov Decision Process) Settings
在 MDP 的配置,其中定义了 observation, action, command 等相关内容。
观测
环境观测量由 ObsGroup 进行统一管理,这里可以在本文件 env_cfg.py 同级目录的 mdp 文件夹中加入一些自定义的观测量,这样在引用时就可以通过 mdp 接口调用了。示例代码如下:
class ObservationsCfg:
"""Observation specifications for the MDP."""
@configclass
class PolicyCfg(ObsGroup): # 定义 policy group
"""Observations for policy group."""
# observation terms (order preserved)
base_lin_vel = ObsTerm(func=mdp.base_lin_vel, noise=Unoise(n_min=-0.1, n_max=0.1)) # 机器人线速度观测项
base_ang_vel = ObsTerm(func=mdp.base_ang_vel, noise=Unoise(n_min=-0.2, n_max=0.2)) # 机器人角速度观测项
projected_gravity = ObsTerm( # 机器人投影到地面的重力加速度观测项
func=mdp.projected_gravity,
noise=Unoise(n_min=-0.05, n_max=0.05),
)
velocity_commands = ObsTerm(func=mdp.generated_commands, params={"command_name": "base_velocity"}) # 机器人速度指令观测项
joint_pos = ObsTerm(func=mdp.joint_pos_rel, noise=Unoise(n_min=-0.01, n_max=0.01)) # 机器人关节位置观测项
joint_vel = ObsTerm(func=mdp.joint_vel_rel, noise=Unoise(n_min=-1.5, n_max=1.5)) # 机器人关节速度观测项
actions = ObsTerm(func=mdp.last_action) # 机器人动作观测项
height_scan = ObsTerm( # 机器人高度扫描观测项
func=mdp.height_scan,
params={"sensor_cfg": SceneEntityCfg("height_scanner")},
noise=Unoise(n_min=-0.1, n_max=0.1),
clip=(-1.0, 1.0),
)
def __post_init__(self):
self.enable_corruption = True
self.concatenate_terms = True
# observation groups
policy: PolicyCfg = PolicyCfg()动作量
class ActionsCfg:
"""Action specifications for the MDP."""
joint_pos = mdp.JointPositionActionCfg(asset_name="robot", joint_names=[".*"], scale=0.5, use_default_offset=True)控制量
class CommandsCfg:
"""Command specifications for the MDP."""
base_velocity = mdp.UniformVelocityCommandCfg(
asset_name="robot",
resampling_time_range=(10.0, 10.0),
rel_standing_envs=0.02,
rel_heading_envs=1.0,
heading_command=True,
heading_control_stiffness=0.5,
debug_vis=True,
ranges=mdp.UniformVelocityCommandCfg.Ranges(
lin_vel_x=(-1.0, 1.0), lin_vel_y=(-1.0, 1.0), ang_vel_z=(-1.0, 1.0), heading=(-math.pi, math.pi)
),
)奖励函数
class RewardsCfg:
"""Reward terms for the MDP."""
# -- task
track_lin_vel_xy_exp = RewTerm(
func=mdp.track_lin_vel_xy_exp, weight=1.0, params={"command_name": "base_velocity", "std": math.sqrt(0.25)}
)
track_ang_vel_z_exp = RewTerm(
func=mdp.track_ang_vel_z_exp, weight=0.5, params={"command_name": "base_velocity", "std": math.sqrt(0.25)}
)
# 奖励措施:希望发生的接触项,权重为 0.125
lin_vel_z_l2 = RewTerm(func=mdp.lin_vel_z_l2, weight=-2.0)
# 惩罚项:希望 actor 在移动时,动作不要快
ang_vel_xy_l2 = RewTerm(func=mdp.ang_vel_xy_l2, weight=-0.05)
# 惩罚项:希望 actor 在移动时,动作不要快
dof_torques_l2 = RewTerm(func=mdp.joint_torques_l2, weight=-1.0e-5)
# 惩罚项:希望 actor 在移动时,动作不要快
dof_acc_l2 = RewTerm(func=mdp.joint_acc_l2, weight=-2.5e-7)
# 惩罚项:希望 actor 在移动时,动作不要快
action_rate_l2 = RewTerm(func=mdp.action_rate_l2, weight=-0.01)
# 奖励项:希望 actor 在移动时,脚并不是一直接触地面,有一些抬起
feet_air_time = RewTerm(
func=mdp.feet_air_time,
weight=0.125,
params={
"sensor_cfg": SceneEntityCfg("contact_forces", body_names=".*FOOT"),
"command_name": "base_velocity",
"threshold": 0.5,
},
)
# 惩罚项:不希望发生的接触项,权重为 -1.0,不希望 actor 与场景中的物体发生碰撞
undesired_contacts = RewTerm(
func=mdp.undesired_contacts,
weight=-1.0, # 这里设置一个较大的惩罚值,防止 actor 与场景中的物体发生严重碰撞
params={"sensor_cfg": SceneEntityCfg("contact_forces", body_names=".*THIGH"), "threshold": 1.0},
)
# -- optional penalties
flat_orientation_l2 = RewTerm(func=mdp.flat_orientation_l2, weight=0.0)
dof_pos_limits = RewTerm(func=mdp.joint_pos_limits, weight=0.0)终止条件
对于一个 locomotion 任务,我们通常会设置如下几个 termination 条件,为什么需要终止条件呢?这是因为,我们希望机器人能够尽快地到达目标位置,因此,当机器人到达目标位置时,我们希望终止当前 episode,从而开始下一个 episode。
@configclass
class TerminationsCfg:
"""Termination terms for the MDP."""
time_out = DoneTerm(func=mdp.time_out, time_out=True) # time out 策略,防止 agent 运行时间过长,一直磨洋工
base_contact = DoneTerm(
func=mdp.illegal_contact, # illegal contact 策略,防止 agent 与场景中的物体发生严重碰撞,导致在实物中发生严重碰撞
params={"sensor_cfg": SceneEntityCfg("contact_forces", body_names="base"), "threshold": 1.0},
)事件
@configclass
class EventCfg:
"""Configuration for events."""
# startup
physics_material = EventTerm(
func=mdp.randomize_rigid_body_material,
mode="startup",
params={
"asset_cfg": SceneEntityCfg("robot", body_names=".*"),
"static_friction_range": (0.8, 0.8),
"dynamic_friction_range": (0.6, 0.6),
"restitution_range": (0.0, 0.0),
"num_buckets": 64,
},
)
add_base_mass = EventTerm(
func=mdp.randomize_rigid_body_mass,
mode="startup",
params={
"asset_cfg": SceneEntityCfg("robot", body_names="base"),
"mass_distribution_params": (-5.0, 5.0),
"operation": "add",
},
)
# reset
base_external_force_torque = EventTerm(
func=mdp.apply_external_force_torque,
mode="reset",
params={
"asset_cfg": SceneEntityCfg("robot", body_names="base"),
"force_range": (0.0, 0.0),
"torque_range": (-0.0, 0.0),
},
)
reset_base = EventTerm(
func=mdp.reset_root_state_uniform,
mode="reset",
params={
"pose_range": {"x": (-0.5, 0.5), "y": (-0.5, 0.5), "yaw": (-3.14, 3.14)},
"velocity_range": {
"x": (-0.5, 0.5),
"y": (-0.5, 0.5),
"z": (-0.5, 0.5),
"roll": (-0.5, 0.5),
"pitch": (-0.5, 0.5),
"yaw": (-0.5, 0.5),
},
},
)
reset_robot_joints = EventTerm(
func=mdp.reset_joints_by_scale,
mode="reset",
params={
"position_range": (0.5, 1.5),
"velocity_range": (0.0, 0.0),
},
)
# interval
push_robot = EventTerm(
func=mdp.push_by_setting_velocity,
mode="interval",
interval_range_s=(10.0, 15.0),
params={"velocity_range": {"x": (-0.5, 0.5), "y": (-0.5, 0.5)}},
)curriculum
常见函数的添加
最后,我们会在 velocity_env_cfg.py 中设置一个完整的LocomotionVelocityRoughEnvCfg(ManagerBasedRLEnvCfg)
@configclass
class LocomotionVelocityRoughEnvCfg(ManagerBasedRLEnvCfg):
"""Configuration for the locomotion velocity-tracking environment."""
# Scene settings
scene: MySceneCfg = MySceneCfg(num_envs=4096, env_spacing=2.5)
# Basic settings
observations: ObservationsCfg = ObservationsCfg()
actions: ActionsCfg = ActionsCfg()
commands: CommandsCfg = CommandsCfg()
# MDP settings
rewards: RewardsCfg = RewardsCfg()
terminations: TerminationsCfg = TerminationsCfg()
events: EventCfg = EventCfg()
curriculum: CurriculumCfg = CurriculumCfg()
def __post_init__(self):
"""Post initialization."""
# general settings
self.decimation = 4
self.episode_length_s = 20.0
# simulation settings
self.sim.dt = 0.005
self.sim.render_interval = self.decimation
self.sim.disable_contact_processing = True
self.sim.physics_material = self.scene.terrain.physics_material
self.sim.physx.gpu_max_rigid_patch_count = 10 * 2**15
# update sensor update periods
# we tick all the sensors based on the smallest update period (physics update period)
if self.scene.height_scanner is not None:
self.scene.height_scanner.update_period = self.decimation * self.sim.dt
if self.scene.contact_forces is not None:
self.scene.contact_forces.update_period = self.sim.dt
# check if terrain levels curriculum is enabled - if so, enable curriculum for terrain generator
# this generates terrains with increasing difficulty and is useful for training
if getattr(self.curriculum, "terrain_levels", None) is not None:
if self.scene.terrain.terrain_generator is not None:
self.scene.terrain.terrain_generator.curriculum = True
else:
if self.scene.terrain.terrain_generator is not None:
self.scene.terrain.terrain_generator.curriculum = False